In my last post I described how at my work we use code review feedback to iteratively improve code. I want to describe how Git fits into this process, because this is probably the biggest change I had to make to my preexisting workflow. Basically I had to relearn how to use Git. The new way of using it (that is, it was new to me) is extremely powerful and in a strange way extremely satisfying, but it does take a while to get used to.
Importance of rebasing
I would describe my old approach and understanding as “subversion, but with better merging” ((Not an insignificant improvement, since merging in Subversion sucks.)). I was also aware of the concept of rebasing from having submitted a pull request to an open source project at one point, but I didn’t use it very often for reasons I’ll discuss later. As it turns out understanding git rebase is the key to learning how to use Git as more than a ‘better subversion’.
For those who aren’t familiar with this command, git rebase <branch> takes the commits that are unique to your branch and places them “on top” of another branch. You typically want to do this with master, so that all your commits for your feature branch will appear together as the most recent commits when the feature branch is merged into master.
Here’s a short demonstration. Let’s say this is your feature branch, which you’ve been developing while other unrelated commits are being added to master:

If you merge without rebasing you’ll end up with a history like this:
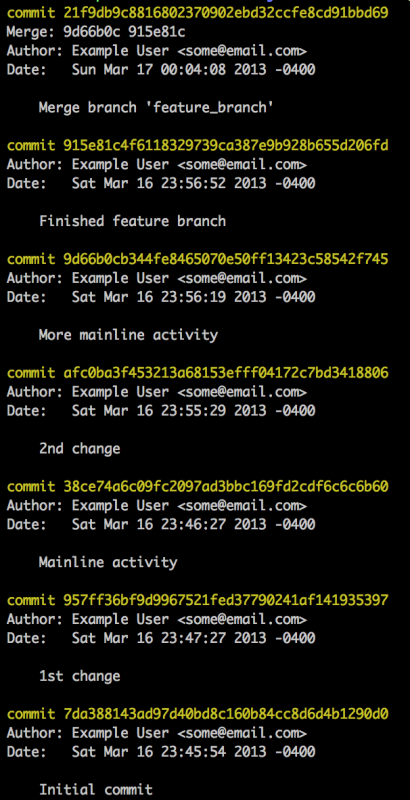
Here is the process with rebasing:
# We're on `feature_branch`
git rebase master # Put feature_branch's commits 'on top of' master's
git checkout master
git merge feature_branch
This results in a clean history:
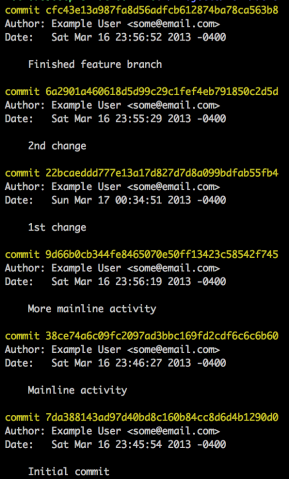
Another benefit of having done a rebase before merging is that there’s no need for an explicit merge commit like you see at the top of the original history. This is because — and this is a key insight — the feature branch is exactly like the master branch but with more commits added on. In other words, when you merge it’s as though you had never branched in the first place. Because Git doesn’t have to ‘think’ about what it’s doing when it merges a rebased branch it performs what is called a fast forward. In this case it moved the HEAD ((Which I always think about as a hard drive head, which I in turn think about as a record player needle)) from 899bdb (More mainline activity) to 5b475e (Finished feature branch).
The above is the basic use case for git rebase. It’s a nice feature that keeps your commit history clean. The greater significance of git rebase is the way it makes you think about your commits, especially as you start to use the interactive rebase features discussed below.
Time travel
When you call git rebase with the interactive flag, e.g. git rebase -i master, git will open up a text file that you can edit to achieve certain effects:
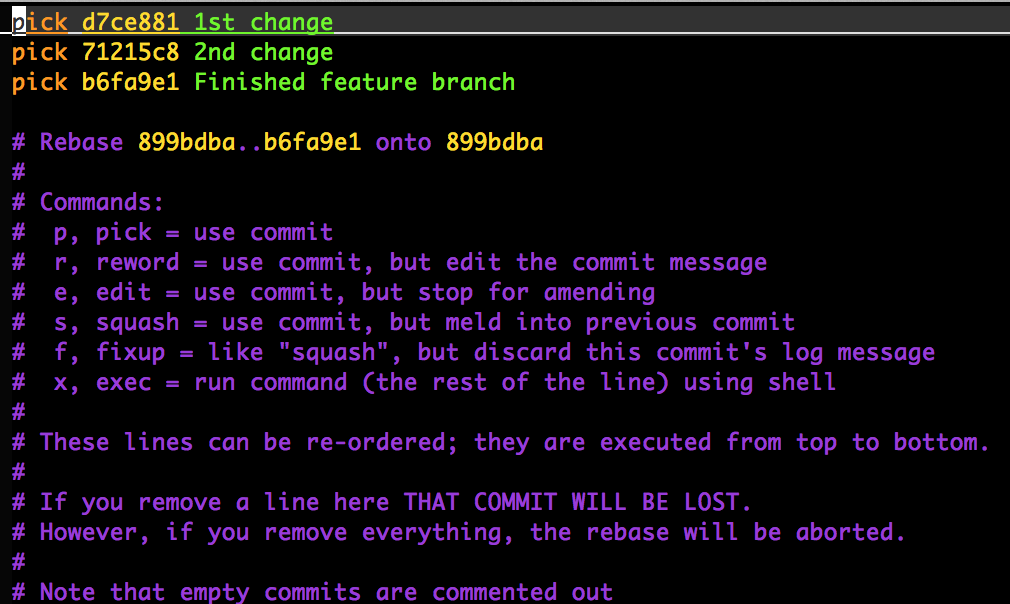
As you can see there are several options besides just performing the rebase operation described above. Delete a line and you are telling Git to disappear that commit from your branch’s history. Change the order of the commit lines and you are asking Git to attempt to reorder the commits themselves. Change the word ‘pick’ to ‘squash’ and Git will squash that commit together with the commit on the preceding line. Most importantly, change the word ‘pick’ to ‘edit’ and Git will drop you just after the selected ref number.
I think of these abilities as time travel. They enable you to go back in the history of your branch and make code changes as well as reorganize code into different configuration of commits.
Let’s say you have a branch with several commits. When you started the branch out you thought you understood the feature well and created a bunch of code to implement it. When you opened up the pull request the first feedback you received was that the code should have tests, so you added another commit with the tests. The next round of feedback suggested that the implementation could benefit from a new requirement, so you added new code and tests in a third commit. Finally, you received feedback about the underlying software design that required you to create some new classes and rename some methods. So now you have 4 commits with commit messages like this:

- Implemented new feature
- Tests for new feature
- Add requirement x to new feature
- Changed code for new feature
This history is filled with useless information. Nobody is going to care in the future that the code had to be changed from the initial implementation in commit 4 and it’s just noise to have a separate commit for tests in commit 2. On the other hand it might be valuable to have a separate commit for the added requirement.
To get rid of the tests commit all you have to do is squash commit 2 into commit 1, resulting in:
- Implemented new feature
- Add requirement x to new feature
- Changed code for new feature
New commit 3 has some code that belongs in commit 1 and some code that belongs with commit 2. To keep things simple, the feature introduced in commit 1 was added to file1.rb and the new requirement was added to file2.rb. To handle this situation we’re going to have to do a little transplant surgery. First we need to extract the part of commit 3 that belongs in commit 1. Here is how I would do this:
# We are on HEAD, i.e. commit 3
git reset HEAD^ file1.rb
git commit --amend
git stash
git rebase -i master
# ... select commit 1 to edit
git stash apply
git commit -a --amend
git rebase --continue
It’s just that easy! But seriously, let’s go through each command to understand what’s happening.
- The first command,
git reset, is notoriously hard to explain, especially because there’s another command,git checkout, which seems to do something similar. The diagram at the top of this Stack Overflow page is actually extremely helpful. The thing about Git to repeat like a mantra is that Git has a two step commit process, staging file changes and then actually committing. Basically, when you rungit reset REFon a file it stages the file for committing at that ref. In the case of the first command,git reset HEAD^ file.rb, we’re saying “stage the file as it looked before HEAD’s change”; in other words, revert the changes we made in the last commit. - The second command,
git commit --amendcommits what we’ve staged into HEAD (commit 3). The two commands together (a reset followed by an amend) have the effect of uncommitting the part of HEAD’s commit that changed file1.rb. - The changes that were made to file1.rb aren’t lost, however. They were merely uncommitted and unstaged. They are now sitting in the working directory as an unstaged diff, as if they’d never been part of HEAD. So just as you could do with any diff you can use
git stashto store away the diff. - Now I use interactive rebase to travel back in time to commit 1. Rebase drops me right after commit 1 (in other words, the temporary rebase HEAD is commit 1).
- I use
git stash applyto get my diff back (you might get a merge conflict at this point depending on the code). - Now I add the diff back into commit 1 with
git commit --amend -a(-a automatically stages any modified changes, skipping thegit add .step).
This is the basic procedure for revising your git history (at least the way I do it). There are a couple of other tricks that I’m not going to go into detail about here, but I’ll leave some hints. Let’s say the changes for the feature and the new requirement were both on the same file. Then you would need to use git add --patch file1.rb before step 2. What if you wanted to introduce a completely new commit after commit 1? Then you would use interactive rebase to travel to commit 1 and then add your commits as normal, and then run git rebase --continue to have the new commits inserted into the history.
Caveats
One of the reasons I wasn’t used to this workflow before this job was because I thought rebasing was only useful for the narrow case of making sure that the branch commits are grouped together after a merge to master. My understanding was that other kinds of history revision were to be avoided because of the problems that they cause for collaborators who pull from your public repos. I don’t remember the specific blog post or mailing list message but I took away the message that once you’ve pushed something to a public repo (as opposed to what’s on your local machine) you are no longer able to touch that history.
Yes and no. Rebasing and changing the history of a branch that others are pulling from can cause a lot of problems. Basically any time you amend a commit message, change the order of a commit or alter a commit you actually create a new object with a new sha reference. If someone else naively pulls from your branch after having pulled the pre-revised-history they will get a weird set of duplicate code changes and things will get worse from there. In general if other people are pulling from your public (remote) repository you should not change the history out from under them without telling them. Linus’ guidelines about rebasing here are generally applicable.
On the other hand, in many Git workflows it’s not normal for other people to be pulling from your feature branch and if they are they shouldn’t be that surprised if the history changes. In the Github-style workflow you will typically develop a feature branch on your personal repository and then submit that branch as a pull request to the canonical repository. You would probably be rebasing your branch on the canonical repository’s master anyway. In that sense even though your branch is public it’s not really intended for public consumption. If you have a collaborator on your branch you would just shoot them a message when you rebase and they would do a “hard reset” on their branch (sync their history to yours) using git reset --hard remote_repo/feature_branch. In practice, in my limited experience with a particular kind of workflow, it’s really not that big a deal.
Don’t worry
Some people are wary of rebase because it really does alter history. If you remove a commit you won’t see a note in the commit history that so and so removed that commit. The commit just disappears. Rebase seems like a really good way to destroy yours and other people’s work. In fact you can’t actually screw up too badly using rebase because every Git repository keeps a log of the changes that have been made to the repository’s history called the reflog. Using git reflog you can always back out misguided recent history changes by returning to a point before you made the changes.
Hope this was helpful!

One thought on “Git workflow”